NeurIPS Workshop on AIM-FM 2024
A self-supervised framework for learning whole slide representations
Xinhai Hou*, Cheng Jiang*, Akhil Kondepudi, Yiwei Lyu, Asadur Chowdury, Honglak Lee, and Todd C. Hollon
University of Michigan, *Equal Contribution
{kind=link}
SPT leverages the inherent regional heterogeneity, feature variability, and information redundancy within WSIs to learn self-supervised representations.
Abstract
Whole slide imaging is fundamental to biomedical microscopy and computational pathology. Previously, learning representations for gigapixel-sized whole slide images (WSIs) has relied on multiple instance learning with weak labels, which do not annotate the diverse morphologic features and spatial heterogeneity of WSIs. A high-quality self-supervised learning method for WSIs would provide transferable visual representations for downstream computational pathology tasks, without the need for dense annotations. We present Slide Pre-trained Transformers (SPT) for gigapixel-scale self-supervision of WSIs. Treating WSI patches as tokens, SPT combines data transformation strategies from language and vision modeling into a general and unified framework to generate views of WSIs for self-supervised pretraining. SPT leverages the inherent regional heterogeneity, histologic feature variability, and information redundancy within WSIs to learn high-quality whole slide representations. We benchmark SPT visual representations on five diagnostic tasks across three biomedical microscopy datasets. SPT significantly outperforms baselines for histopathologic diagnosis, cancer subtyping, and genetic mutation prediction. Finally, we demonstrate that SPT consistently improves whole slide representations when using off-the-shelf, in-domain, and foundational patch encoders for whole slide multiple instance learning.
Motivation
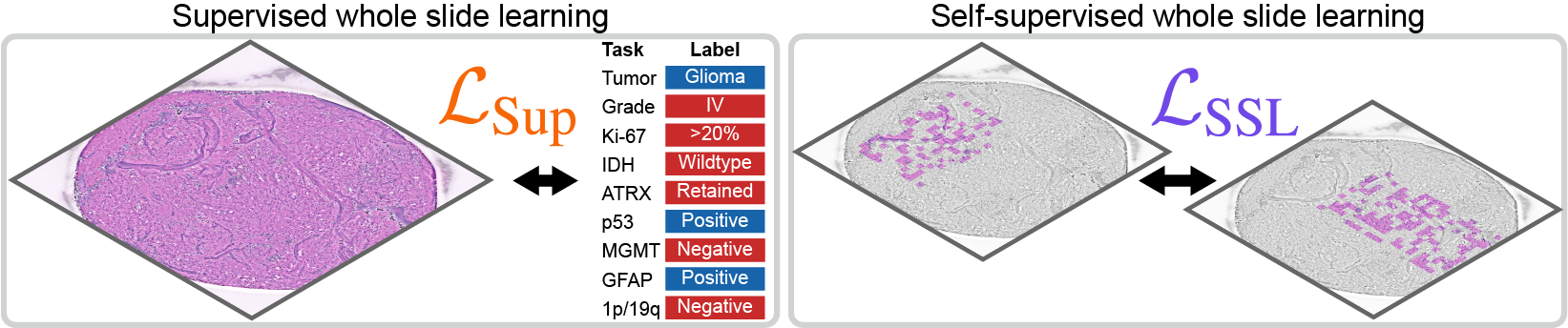
Self-supervised whole slide learning. Previous work in computational pathology relies on multiple instance learning with weak supervision from slide or patient-level labels to learn whole slide representations. Slide Pre-trained Transformers (SPT) is a self-supervised framework for learning whole slide representations, that combines data transformations from vision and language modeling to generate high-quality paired views.
SPT overview
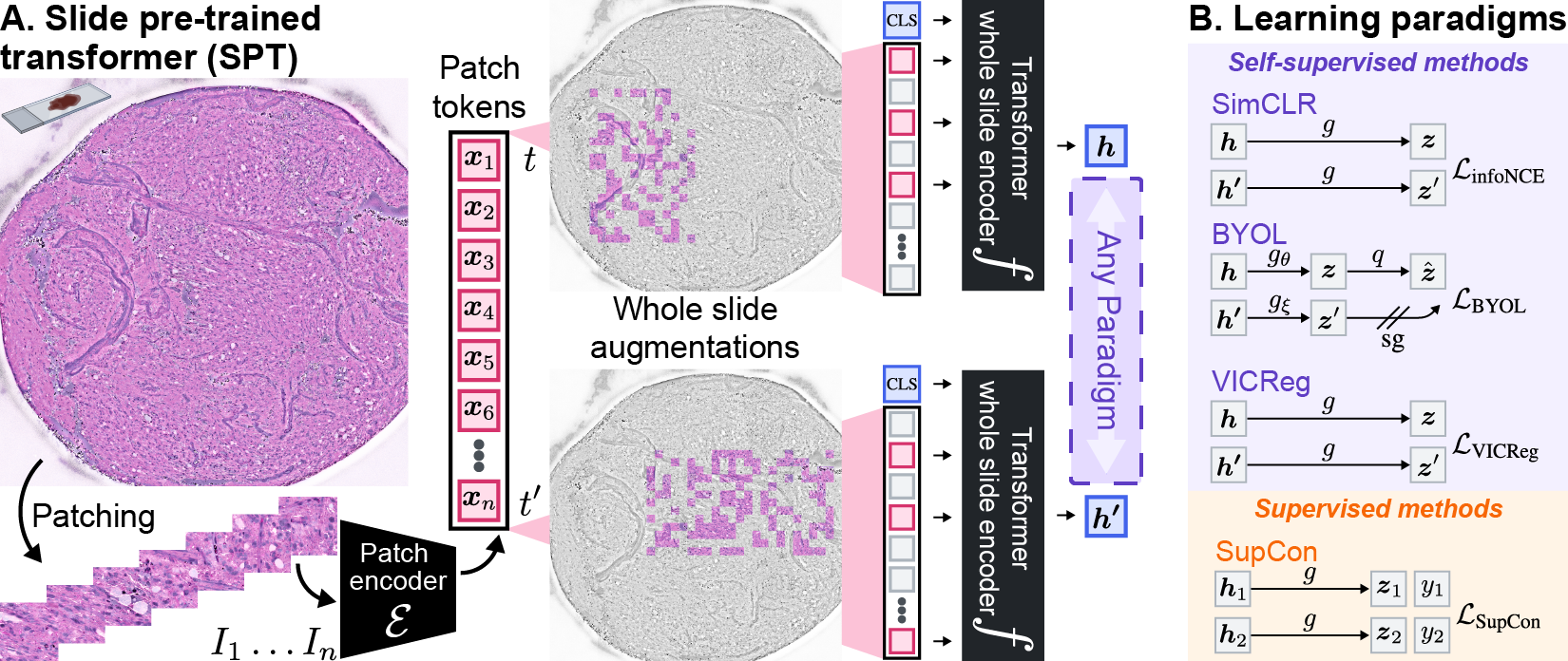
A. The SPT framework consists of a two-stage model architecture: 1) a pre-trained patch encoder and 2) a transformer whole slide encoder. WSIs are first divided into small patches, and the patch encoder extracts patch-level features. We then apply whole slide transformations to the patch tokens to create two views of the same WSI. The transformations combine splitting, cropping, and masking, which are informed by the structure and unique properties of WSIs. The transformed views are encoded by the transformer whole slide encoder, and the slide-level feature learning can use any paradigm. B. Example learning paradigms. In our experiments, we focus on three representative self-supervised paradigms, including SimCLR, BYOL, and VICReg, and supervised contrastive learning.
Bibtex
@article{hou2024self,
title={A self-supervised framework for learning whole slide representations},
author={Hou, Xinhai and Jiang, Cheng and Kondepudi, Akhil and Lyu, Yiwei and Chowdury, Asadur Zaman and Lee, Honglak and Hollon, Todd C},
journal={arXiv preprint arXiv:2402.06188},
year={2024}
}